
Ingestion into DataLake Without Illusions
When the Tools Fall Short


The foundational promise of the modern data stack was a seductive one: that data ingestion could be reduced to a commodity utility, a set of plug-and-play connectors that would liberate data engineers from the drudgery of "glue code" and allow them to focus on high-value analytics. For nearly a decade, this narrative fueled the meteoric rise of companies like Fivetran and dbt Labs, predicated on the idea that the "best-of-breed" modularity of a fragmented stack was inherently superior to the monolithic architectures of the past. However, as these systems have encountered the reality of petabyte-scale ingestion, complex multi-tenant requirements, and the stringent demands of the data lakehouse, the "Modern Data Stack" has transitioned from a celebrated innovation to a source of profound technical and economic disillusionment.
Current practitioner sentiment across communities like Reddit and Hacker News suggests that the Data Stack is increasingly viewed as a "Rube Goldberg-esque"1 infrastructure that consumes up to 80% of an engineering team’s bandwidth just to keep the lights on. The modular dream has mutated into a maintenance nightmare characterized by unmanageable tool sprawl, opaque usage-based costs, and a fragmentation of metadata that leaves organizations with no single source of truth. This report analyzes the technical failures of the industry’s primary ingestion tools, the strategic implications of the recent Fivetran–dbt merger, and the emerging engineering philosophies designed to move the industry past the illusions of "plug-and-play" data movement.

The Technical Erosion of Managed Ingestion Tools
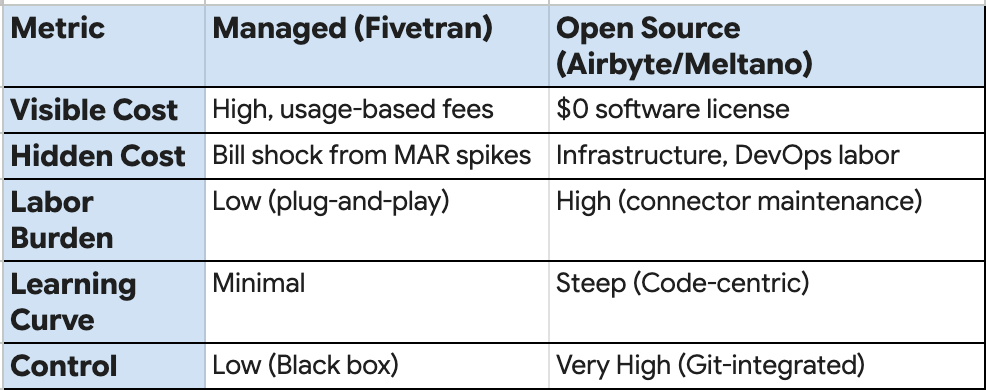
The primary critique leveled against the current generation of ingestion tools—specifically Fivetran, Airbyte, and Meltano—is that they often prioritize ease of initial setup over long-term operational stability and cost predictability. While Fivetran may offers the "purest" managed experience, its architectural choices and billing practices have led to widespread skepticism among practitioners who value transparency and control. Conversely, open-source alternatives like Airbyte and Meltano, while offering greater flexibility, introduce significant operational "taxes" that are often understated in their marketing materials.
Building a data lake is often perceived as a simple act of "dumping" data into cheap storage, but the reality of ingestion involves complex trade-offs between managed convenience and open-source flexibility. Organizations frequently underestimate the "operational taxes" associated with both paths, leading to either unpredictable billing or significant engineering debt.
1. Fivetran and the Black-box Illusion of Predictability

Fivetran is often cited as the "purest" managed experience, yet practitioners increasingly voice skepticism regarding its architectural choices and billing transparency. 2 Specifically:
The “MAR” Billing and “Resync Tax”
The central friction point is the Monthly Active Rows (MAR) model. Users frequently encounter “bill shock” because the logic for what constitutes an “active” row is often opaque and proprietary.
Unpredictability: Technical operations, such as a database migration or a broad column-type update, can trigger massive row counts, effectively acting as a “resync tax” on necessary maintenance.
Throughput Constraints: Despite high costs, users have reported transfer speeds topping out at 5MB/s during full resyncs, making recovery for terabyte-scale databases a process that can take weeks.
Architectural Opacity
Critics describe Fivetran as a "black box" where business logic is buried, making audits and incident debugging complex undertakings. A specific technical critique involves Fivetran's allegedly problematic handling of the Postgres Write-Ahead Log (WAL); if the ingestion engine requires a log that has been rotated, the pipeline may get "stuck," necessitating a full, expensive resync.
2. The Open-Source Reality: Navigating Operational Taxes

Open-source alternatives like Airbyte and Meltano offer transparency and avoid vendor lock-in, but they introduce a "DevOps tax" that is often understated.
The Airbyte “DevOps Tax”
Self-hosting Airbyte requires significant infrastructure management, including Kubernetes orchestration, backups, and security patching.
Maintenance Effort: While Airbyte offers 600+ connectors, only about 150 are officially maintained. The remainder are community-contributed and can be “brittle and immature” at scale, forcing engineers to spend substantial time “babysitting” and debugging silent failures.
Operational Overhead: Organizations often underestimate the labor hours required; some users report that self-hosting issues can occur several times a month, each taking hours to resolve.
The Meltano “Engineering Tax”
Meltano follows a “code-first” philosophy that appeals to developers but imposes a steep learning curve for non-technical users.
Talent Requirements: Managing Meltano's plugin-based architecture requires specialized skills in Python and YAML. For teams lacking this foundation, the cost of compute and support labor often outweighs any software savings.
Dependency Hell: Because Meltano orchestrates various plugins (e.g., Singer taps/targets, dbt models), maintaining compatibility after updates becomes a complex governance task that can lead to “pipeline rot.”
3. Total Cost of Ownership (TCO) Spectrum

The decision between managed and open-source is essentially a choice of where to pay the "tax": in OpEx fees or human capital. And the human capital is the largest and most frequently underestimated expense in the open-source path.
4. Technical Debt: The Data Swamp Consequences

Poorly managed ingestion, regardless of the tool, leads to “ingestion debt” and the creation of a “data swamp.”
Schema Drift: Source systems evolve independently; without automated detection (CDC), a simple column rename can break downstream dashboards instantly.
Over-partitioning: Creating too many small files can slow query performance significantly. A partitioned query may take 30 seconds, while an unpartitioned one can take over 4 minutes.
Observability Gaps: When pipelines lack metadata and lineage, debugging becomes nearly impossible. Practitioners report that analytics teams can spend up to 35% of their time explaining why numbers differ rather than generating insights.
5. Strategic Synthesis: Breaking the Binary Choice with the “Third Way”
Modern software engineering" has traditionally forced teams into a binary deadlock: paying a heavy "managed service tax" (high variable costs and vendor lock-in) or a heavy "operational tax" (unmanageable infrastructure and labor overhead). Recognising that neither path is ideal, I am always curious about "Third Way" strategy —a hybrid approach designed to combine the benefits of both while ensuring the combined cost is lower than either individual option.
The Philosophy of Combined Efficiency
To address this binary deadlock, I built dativo-ingest as a framework that rejects the trade-off between control and convenience. This strategy optimizes the tax burden by accepting a minimized version of both:
Eliminating the Managed Markup: Instead of paying high MAR premiums for simple replication, the Third Way uses automated, Python-native libraries to control exactly what is synced. This avoids the “money grabs” common in managed platforms where unrequested tables or vendor-default settings inflate bills.
Decoupling from Infrastructure Chaos: By utilizing lightweight frameworks that live in Git and deploy via standard CI/CD, teams avoid the “DevOps tax” of managing dedicated Kubernetes clusters. Ingestion is treated as a software component within the existing engineering stack, not as a standalone platform to be “babysat”.
Implementation: Spec-Driven Development (SDD)
I believe, that a core pillar of this Third Way is Spec-Driven Development (SDD). Rather than relying on “vibe-coding” (ad-hoc prompts and conversational configuration), frameworks like dativo-ingest utilize formal specifications as the source of truth.
Architectural Firewalls: SDD allows teams to build production-ready pipelines with up to 95% accuracy on the first implementation. This ensures that human developers and AI agents alike can maintain consistent, maintainable, and highly auditable pipelines.
Unified Control Plane: This model permits organizations to pay a negligible “operational tax” for code maintenance and a small “service tax” for the underlying compute (e.g., Lambda or serverless executors). The result is an ingestion engine that provides the transparency of open-source with the speed of managed automation, without the scaling headaches of either.
In the context of actual infrastructure, the term implies systems that are:
Overly complex: Involving many unnecessary steps or components.
Inefficient: Disproportionate to the simplicity of the goal they achieve.
Convoluted: Difficult to understand, manage, or maintain due to their complexity.
Prone to failure: A breakdown in any single, non-essential link can disrupt the entire process.
The perfect problem statement - “Why is it so hard to buy things that work well?” https://news.ycombinator.com/item?id=42430450