
If we redact PII before the model sees the prompt, can we still preserve enough context for good reasoning?
Same privacy boundary. Better answers. Measured across 200 A/B prompts.


Most teams still talk about privacy and model quality as if you can only have one.
Either you protect sensitive data, or you preserve enough context for the model to be useful.
That tradeoff sounds intuitive. It is also too simplistic.
Ideally with tools like Talon, raw PII never reaches the model. But there is a big difference between removing PII and removing meaning.
A flat placeholder like [PHONE] protects privacy, but it also hides the one thing the model may actually need to answer correctly: is this a German number, a Polish number, or a French one?
So I tested a different approach.
Instead of sending raw personal data to the model, Talon can replace it with structured placeholders that preserve only safe, task-relevant semantics. Not the original value. Just the minimum useful context.
And when I compared that enriched approach against legacy type-only redaction, the enriched version won in both evaluation runs.
TL;DR
I ran two 100-prompt A/B evaluations on Dativo Talon to test a simple question: if we redact PII before the model sees input, can we still preserve enough meaning for useful reasoning? Answer: yes. Enriched redaction (semantic placeholders) beat legacy type-only redaction in both runs, especially on attribute-dependent tasks like country routing and payment-method decisions.
The setup
I tested two variants.
Variant A: legacy redaction
The model sees flat placeholders such as [PERSON], [EMAIL], [PHONE], [IBAN].
Variant B: enriched redaction
The model sees structured placeholders such as:
<PII type=”phone” country_code=”PL”/>or
<PII type=”email” domain_type=”free”/>In both cases, raw PII is removed before model input.
This is not a comparison between “private” and “non-private.” Both variants keep raw personal data away from the model. The only difference is whether the model still receives safe semantic hints that matter for the task.
I ran two full experiments:
Run 1:
gpt-4o-mini, 100 prompts. See full logsRun 2:
gpt-4o, 100 prompts. See full logs
Each prompt was scored on four dimensions, from 1 to 10:
attribute reasoning(“context”)
utility preservation
semantic coherence
helpfulness
So each prompt had a maximum total score of 40.
What happened
Run 1 — gpt-4o-mini (N=100)
A mean total: 23.87
B mean total: 28.58
Mean delta: +4.71
Numeric wins: B 59, A 19, ties 22
Run 2 — gpt-4o (N=100)
A mean total: 23.5
B mean total: 30.2
Mean delta: +6.7
Numeric wins: B 63, A 26, ties 11
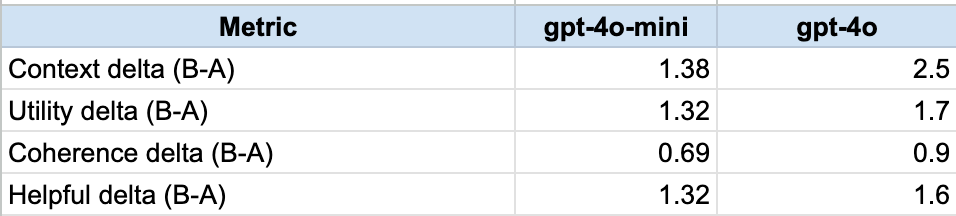
Enriched redaction wins in both runs.
The strongest lift is exactly where it should be: attribute reasoning.
Where enrichment helped most
Not all semantic attributes are equally valuable.
The strongest gains came from attributes that directly affect routing, jurisdiction, or payment behavior.
Strongest lift
PHONE →
country_codeIBAN →
country_code
This was the clearest signal in both runs.
If the model sees only [PHONE], it cannot reliably decide whether the request belongs with Germany, Poland, France, or another support flow.
If it sees <PII type="phone" country_code="DE"/>, that ambiguity disappears without exposing the original number.
The same pattern showed up for IBANs. A country code is often enough to reason about SEPA, local handling, or country-specific banking logic.
Moderate lift
PERSON →
genderEMAIL →
domain_type
These still helped, but less dramatically.
That also makes sense.
A corporate email domain or a gendered title can improve the answer, but the downstream task is often less deterministic than country-based routing. The model can sometimes get close with generic language even without the attribute.
Weakest area
LOCATION →
scopesuch as city, region, or country
This was the least convincing category.
The issue was not necessarily the enrichment itself. It was the prompt design.
Too many location prompts could still be answered with generic legal boilerplate. If a question does not force the model to actually use the distinction between city, region, and country, then that attribute will not show its value.
So this is less “scope does not help” and more “the benchmark did not pressure-test scope hard enough.”
What this means in practice
This is the production lesson.
Most teams fall into one of two bad patterns.
The first is to send raw prompts with PII to the model and hope governance happens somewhere later.
The second is to over-redact everything into useless placeholder soup and then act surprised when the model starts guessing.
Neither is a good long-term design.
The better path is narrower and more disciplined:
remove raw PII before the model sees it
preserve only the minimum safe semantics needed for reasoning
decide those semantics through policy
record evidence of what the model actually saw
That is the operating model Talon is built around, and this evaluation supports it.
Edge cases worth being honest about
The result is strong, but not perfect.
A few caveats matter.
1. Prompt quality still varied
Some prompts were genuinely attribute-dependent. Others were only loosely so.
That matters because if a prompt can be answered with generic common sense, the benchmark becomes less discriminative.
2. Judge behavior still has style bias
In a few cases, longer and more generic answers scored surprisingly well, even when a shorter answer was more precise.
That is a familiar problem in LLM-as-judge evaluations.
3. Order effects were more visible on the smaller model
I saw a bit more sensitivity in the gpt-4o-mini run than in the gpt-4o run.
Not enough to change the direction of the result, but enough to keep in mind.
4. Location-scope prompts need to be redesigned
This was the weakest benchmark segment and the one I would trust least in its current form.
So yes, the result is real. But some parts of the evaluation are stronger than others.
What about cost?
This is usually the first practical objection.
Semantic placeholders are longer. So do they make inference meaningfully more expensive?
In these runs, not in a way that mattered.
In the
gpt-4o-minirun, Variant B was slightly cheaper overall.In the
gpt-4orun, Variant B was materially cheaper in observed run cost.
That does not mean enriched placeholders are inherently cheaper token-for-token. They are not.
It means end-to-end cost is dominated by full model behavior, especially output length and answer shape, not just placeholder size.
So the real takeaway is simpler:
The quality gain was clear, and the added redaction structure did not create a practical cost penalty.
Why This Matters for Production
Most teams still run one of two broken patterns:
send raw prompts with PII and hope policy catches up later, or
over-redact into useless
[TYPE]soup and lose utility.
There is a better middle path:
remove raw PII from model input
preserve a minimal, safe semantic layer
apply policy-as-code to which attributes are allowed
keep evidence for what the model actually saw
That is what this experiment validates.
What we are changing next in Talon
Based on these runs, here is what I would do next:
Keep enriched redaction as the default for supported models.
Improve the location-scope benchmark, especially prompt quality and dictionaries.
Use a separate judge model and add a small human-reviewed subset.
Run multi-seed evaluations with confidence intervals in CI.
The core result is already useful. But the next version of the benchmark should be harder, cleaner, and more defensible.
Final Thought
Privacy-preserving AI does not need to be blind AI.
If your redaction layer removes everything useful, the model will guess.
If your redaction layer keeps safe semantics, the model can still reason.
This is not a theoretical point. We measured it across 200 prompt pairs.
No raw PII to the model. Better answers anyway.