
How to Manage AI Spending Before It Becomes Cloud Spend Again
Why AI Cost Control is Becoming an Infrastructure Problem


Over the last few months, I’ve seen the same problem appear across drastically different companies:
Startups trying to rein in spiraling coding-agent bills.
SMBs aggressively adding AI to their support and operations pipelines.
Enterprises opening the floodgates by giving employees access to multiple AI tools.
Despite the different contexts, they are all asking the same question: “How do we manage AI spending without blocking useful AI work?”
This question isn’t arising because AI failed. It’s happening because AI started working well enough to become expensive. As Reuters recently noted, while base token prices are falling, real AI bills are still rising. Today’s tasks utilize longer contexts, more steps, massive files, multiple retries, and complex agentic workflows. Smart companies are beginning to shift routine work to cheaper models, reserving expensive frontier models for only the hardest tasks.
That is the right pattern. But to execute it, you need infrastructure.
Token Spend Behaves Exactly Like Cloud Spend
AI spending is mirroring the early days of cloud computing. The cycle is predictable:
Usage is heavily encouraged to drive innovation.
Every team adopts it.
A massive, unexpected bill arrives.
Finance scrambles to ask who owns the spend.
The exact same phenomenon that happened with compute and storage is now happening with tokens. The WSJ recently highlighted companies applying traditional cloud FinOps patterns to AI token spend: dashboards, spend caps, showback, chargeback, smaller models, and strict usage accountability.
This is where the industry is heading. The solution is not to “ban AI” or blindly force the cheapest model everywhere. The solution is controlled AI usage categorized by team, application, model, and data type.
The Core Problem: Direct Model Access
During the experimentation phase, most AI usage looks like a spiderweb of direct connections:
Slack bot → OpenAI
Coding agent → Anthropic
Internal app → OpenAI
Support tool → Claude
Employee → Personal AI account
Vendor AI → Unknown model
This works well for prototypes, but it shatters in production. Every direct path creates its own siloed cost behavior, model preference, data retention assumption, API key, log system, and compliance risk. At a company scale, this architecture leaves leadership unable to answer basic questions:
Which teams are spending the money?
Which models are they actually using?
Which requests contain PII?
Which vendor saw which sensitive data?
This is why AI cost control cannot happen after the fact. It must happen at the traffic layer.
The Practical Controls Companies Need
If a company wants to manage AI spending properly, it needs to implement controls before the model call happens.
1. Caller Identity
Every AI request must be tied to an application or team identity (e.g., support-slack-bot, engineering-coding-agent, finance-document-assistant). Without caller identity, cost ownership is impossible.
2. Per-Caller Budgets
Each caller should have hard daily and monthly limits. This is the AI equivalent of cloud budget alerts, but the crucial difference is that the request is denied before the spend happens.
YAML
gateway:
callers:
- name: support-slack-bot
tenant_id: support
policy_overrides:
max_daily_cost: 10.00
max_monthly_cost: 200.00
3. Model Allowlists
Not every team needs access to a frontier model. Routine support, text classification, summarization, and internal search can operate perfectly on lighter models.
YAML
policy_overrides:
allowed_models:
- gpt-4o-mini
- claude-haiku
4. Intelligent Model Routing
The golden rule is not “use the cheapest model.” The rule is: Use the cheapest model allowed for this specific request.
Public data can route to cheap models.
Sensitive data may require EU routing.
HR and legal tasks require strict zero-retention policies.
5. Context and Loop Limits
Agentic coding and document workflows can burn tokens silently. Recent studies on agentic tasks show that token usage can vary by up to 30x for the exact same task—and higher usage doesn’t always equal higher accuracy. You need circuit breakers:
YAML
policies:
resource_limits:
max_iterations: 10
max_tool_calls_per_run: 20
max_cost_per_run: 0.50
6. Semantic Caching
If hundreds of users ask a similar question, the system should not call the LLM every time. Caching public or low-risk answers is the fastest way to slash inference costs. However, caching must be aware of context: strictly avoid caching PII, confidential data, or dynamic tool calls.
Why Price Isn’t Enough: The Claude Fable 5 Example
Claude Fable 5 perfectly illustrates why AI spending is fundamentally a routing problem, not just a cost problem.
Fable-class models are phenomenal for heavy lifting: deep analytics, massive context windows, and complex autonomous agents. However, they come with premium pricing and operational sensitivity. Reuters recently reported that companies like Microsoft have had to restrict employee use of advanced models like Fable 5 due to data-retention concerns.
The most capable model isn’t always the right model. While Fable 5 might be perfect for public code analysis, it may need to be blocked entirely for zero-data-retention workloads in HR or healthcare. This proves that model choice should never be hardcoded into an application; it must be dictated by a centralized policy.
The Solution: Enter Talon
Talon introduces a much-needed control layer between your applications and the model providers. Instead of an unmanageable web of direct API calls, Talon centralizes the traffic.
Before forwarding any request, Talon can automatically:
Identify the caller and evaluate their policy.
Check rate limits and estimate the cost.
Scan for PII and classify the data tier.
Filter dangerous tools and redact sensitive text.
Route the prompt to the cheapest allowed provider.
Record cryptographically signed evidence of the transaction.
AI cost control should not be a depressing monthly report; it should be a real-time, automated runtime decision.
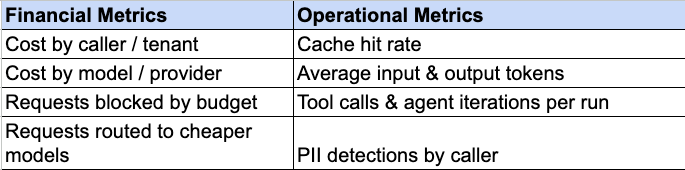
What to Measure
To effectively govern this new infrastructure, move away from looking at a single, terrifying AI bill. Instead, track these specific metrics to see exactly where your spend is coming from and whether your policies are working:
Final Thoughts
Direct provider access is perfectly fine for early prototypes or low-risk, public-data applications. But once AI becomes shared, expensive, sensitive, or agentic, direct access is the wrong abstraction.
You cannot control AI spending by simply asking developers to “use fewer tokens”—that didn’t work for cloud compute, and it won’t work now.
Cheaper models, caching, and better prompting will help, but ultimately, companies need a centralized control point. AI is no longer just a neat tool employees play with; it is core traffic moving through your company’s nervous system. And traffic needs policy before it becomes spend.